احتمالا بعنوان یه هکر اخلاقی، توسعه دهنده ابزار و … ، اتفاق افتاده که در پروژه ای نیاز به دور زدن کلودفلر باشید. ابزارهای مختلفی رو تست کرده باشید و از بعضی هاشون نتیجه گرفته باشید و بعضی هاشون ناامیدتون کردن.
در این پست به بررسی مقاله اخیر Scrapeops در زمینه تکنیکهای دور زدن کلودفلر پرداختیم. این کمپانی توسعه دهنده ابزارهای Web Scraping مبتنی بر هوش مصنوعی هستش. البته روشهایی که گفته فقط در زمینه Web Scraping کاربرد نداره و میشه در مواردی که نیاز به دور زدن کلودفلر هست، استفاده بشه.
آشنایی با Web scraping :
Web scraping یا استخراج داده ، تکنیکی هستش که در اون بصورت خودکار یسری داده رو از سایتها و صفحات HTML استخراج میکنن.
معمولا زمانی استفاده میشه که سایت API خاصی ارائه نمیده تا بقیه بتونن با استفاده از اون داده ها رو استخراج کنن و ما مجبوریم مستقیم سراغ خود سایت بریم.
هدف از Web scraping تبدیل داده های بدون ساختار HTML به داده های سازگار و آنالیز داده ها هستش.
web scraping با web crawling فرق داره. معمولا از web crawling برای پیمایش و پروفایل کردن سایتها استفاده میشه. مثلا موتورهای جستجو ، با استفاده از این تکنیک ، سایتها رو ایندکس میکنن. اما در web scraping هدف جمع آوری داده ها هستش. اغلب به دلیل اینکه این دو روش در کنار هم استفاده میشن، به نظر یکی میان. یعنی با web crawling سایت پیمایش میکنن و با web scraping داده ها رو جمع آوری میکنن.
افراد مختلفی از web scraping استفاده میکنن مثلا : مقایسه قیمت محصولات یه سایت، بررسی فعالیت شبکه های اجتماعی ، بررسی رتبه بندی گوگل و بینگ و … . در زمینه باگ بانتی و امنیت هم میشه از web scraping استفاده کرد مثلا جمع آوری برنامه های موجود در پلتفرم های باگ بانتی، استخراج داده از سایت هدف و … .
بطور کلی اگه بخوایین داده های زیادی رو از یه سایتی استخراج کنید، یا بخواییم که از یه سایت بطور منظم ، مثلا بطور روزانه، داده استخراج کنید، web scraping به کمکمون میاد.
آشنایی با کلودفلر:
کلودفلر یکی از بزرگترین شبکه های CDN جهان هستش که تخمین زده میشه، 40 رصد سایتهای دنیا از سرویس CDN کلودفلر استفاده میکنن.
این سرویس مثله یه واسط بین مرورگر بازدید کننده و سرور سایت قرار میگیره، در نتیجه میتونه باتها و هکرها رو شناسایی و اونارو مسدود کنه. در نتیجه میتونه در فرایند web scraping ما هم اختلال ایجاد کنه.
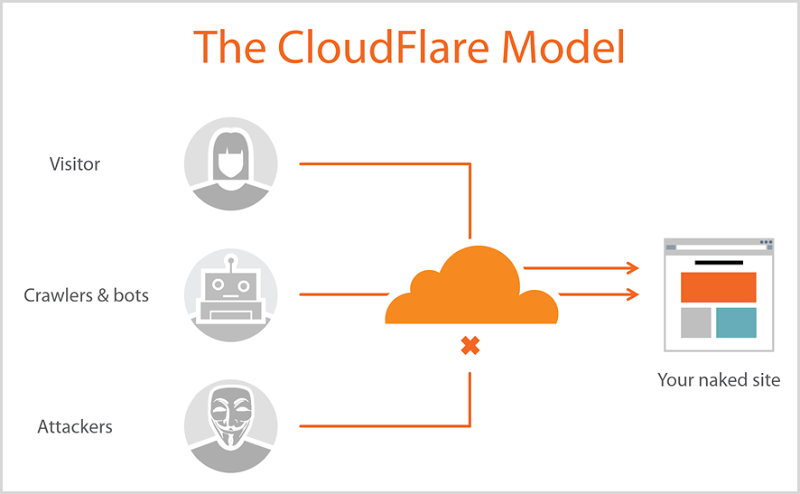
روشهایی مختلفی برای دور زدن کلودفلر وجود داره که هر کدوم مزایا و معایبی داره، که در این پست ، به برخیاشون اشاره میشه.
در کل روشهایی که مورد بررسی قرار گرفتن :
- ارسال درخواستها به سرور مبدا
- اسکرپینگ نسخه کش گوگل
- حل کننده های چالش های کلودفلر
- اسکرپینگ با Headless Browsers های تقویت شده
- مهندسی معکوس آنتی بات کلودفلر
- پروکسی هوشمند با امکان دور زدن Cloudflare
در پایان پست ،شما با روشهای مختلف دور زدن کلودفلر آشنا میشید و میتونید در شرایط مختلف بهترین روش رو انتخاب کنید.
1- ارسال درخواستها به سرور مبدا:
اگرچه همیشه ممکن نیست، اما ساده ترین روش برای دور زدن کلودفلر اینه که IP سرور اصلی رو بدست بیاریم و درخواستهامون رو به اون ارسال کنیم.
در این روش به جای اینکه کلودفلر رو فریب بدیم که درخواستهای ما از یه کاربر واقعیه، به کل ، اونو دور می زنیم.
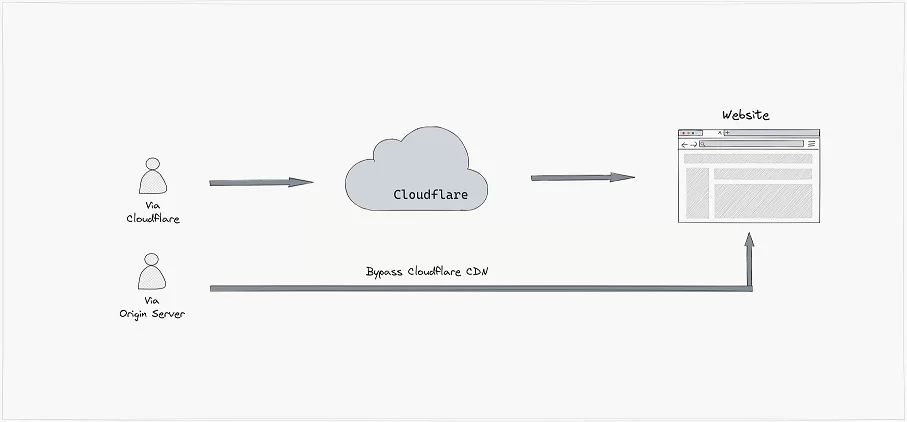
اگرچه کلودفلر یه سیستم پیچیده ای داره ، اما در نهایت توسط یه انسان کانفیگ میشه و شامل اشتباهات انسانی هستش. برهمین اساس گاهی با کمی جستجو میشه IP سرور رو بدست آورد.
با بدست آوردن این IP، میشه از اون در scraper خودمون استفاده کنیم.
گاهی اوقات با زدن IP در مرورگر ، نمیشه وارد اون سایت شد، چون سرور انتظار داره که در درخواست، یه هدر HOST رو مشاهده کنه. در این شرایط میتونید از ابزارهایی مانند curl یا Postman که امکان ست کردن این هدر دارن، استفاده کنید.
1-1- پیدا کردن IP سرور مبدا
روش های مختلفی برای بدست آوردن IP سرور هستش که در اینجا به سه روش محبوب اشاره شده :
1-1-1-روش اول: گواهینامه های SSL
اگه وب سایت از SSL استفاده کنه، گواهی SSL اون در Censys ثبت میشه. اگه سایت در پشت کلودفلر باشه، در برخی مواقع گواهی SSL قدیمی یا فعلیشون روی سرور اصلی ثبت میشه. بنابراین میتونید با جستجو در Censys این موارد بررسی کنید.
1-1-2-رکوردهای DNS سرویس های دیگه
گاهی اوقات سابدومین ها ، سرورهای ایمیل (MX) ، سرویس های FTP/SCP یا hostnameها ، روی همون سرور میزبانی میشن که وب سایت اصلی روشه و پشت کلودفلر نیست.
در این شرایط میتونید رکوردهای DNS رو برای سابدومین ها ، A ، AAAA ، CNAME و MX در شودان یا Censys بررسی کنید.
اگه سایت از ارائه دهنده ایمیل شخص ثالث استفاده نکنه، یه روش اینه که یه ایمیل به یه آدرسی که در سایت وجود نداره، ارسال کنید. اگه ایمیل ارسال نشه، یه نوتیفیکیشن برای عدم ارسال ایمیل از سرور ایمیل که حاوی آدرس IP هستش، میگیرید.
1-1-3-رکوردهای DNS قدیمی :
تاریخچه DNS هر سروری در اینترنت قابل دسترس هستش. بنابراین اگه سایت روی سروری که قبل از اینکه بره پشت کلودفلر میزبانی میشد، باشه ، با ابزارهایی مانند CrimeFlare، اطلاعات مفیدی میشه ازش استخراج کرد.
1-1-4-ابزارها :
در زیر برخی ابزارهایی که برای بدست آوردن IP میتونن کمکتون کنن وجود داره :
توجه کنید که برخی اوقات، ادمین سایتها، سرور طوری کانفیگ میکنن که فقط به محدوده IP مرتبط با کلودفلر پاسخ بدن، در نتیجه بدست آوردن IP زیاد کاربردی نیست.
گاهی اوقات شما یه سرور مبدا رو پیدا میکنید ، اما ممکنه این سرور بعنوان سرور توسعه یا … برای سایت اصلی باشه. اگه نمیتونید 100 درصد مطمئن بشید که این دو تا یکی هستن ،میتونید از این روش استفاده کنید که یه اکانت در سایتی که روی سرور مبدا هست، باز کنید و بعدش بیایید رو سایتی که پشت کلودفلر هست و لاگین کنید و رفتار رو بررسی کنید. اگه رفتار مشابهی داشته باشن، بنابراین IP ای که پیدا کردید مربوط به سایت اصلی هستش.
مقالات زیر هم میتونن در پیدا کردن IP کمکتون کنه :
- Bypassing Cloudflare WAF with the origin server IP address
- Introducing CFire: Evading CloudFlare Security Protections
- CloudFlair: Bypassing Cloudflare using Internet-wide scan data
در نهایت اگه نتونستید که IP سرور مبدا رو پیدا کنید، نگران نباشید و روش های بعدی رو امتحان کنید.
2- اسکرپینگ نسخه کش گوگل :
بسته به اینکه داده هایی که از سایت استخراج میکنید چه اندازه باید جدید باشه، میتونید بجای اسکرپینگ خود سایت، از Google Cache استفاده کنید.
وقتی گوگل سایتها رو برای ایندکس کردن صفحات جدید کراول میکنه، یه کش از داده هایی که پیدا کرده، ایجاد میکنه. خیلی از سایتهایی که پشت کلودفلر هستن، امکان کراول کردن رو به گوگل میدن و شما میتونید از اونا استفاده کنید.
اگه بحث تازه بودن داده های سایت مهم نباشه، اسکرپینگ کش گوگل ساده تر از اسکرپینگ خود سایته. برای اینکار کافیه ، سایت مدنظرتون رو به انتهای این آدرس اضافه کنید :
|
1 |
https://webcache.googleusercontent.com/search?q=cache |
برای مثال اگه بخوایید سایت https://www.petsathome.com/shop/en/pets/dog رو اسکرپ کنیم، آدرستون بصورت زیر میشه :
|
1 |
'https://webcache.googleusercontent.com/search?q=cache:https://www.petsathome.com/shop/en/pets/dog' |
این روش هم دو تا عیب داره، یکی اینکه ممکنه برخی سایتها به گوگل بگن که سایتشون رو کش نکنه. برای مثال لینکدین اجازه کش کردن برای گوگل رو نمیده. مورد بعدی هم اینه که ممکنه میزان کراول کردن گوگل خیلی پایین باشه یعنی اینکه صفحات کمی از سایت توسط گوگل کراول بشن. در نتیجه برای اسکرپینگ اون صفحات دستتون بسته باشه.
3- حل کننده های چالش های کلودفلر:
اگه نتونید سرور مبدا رو پیدا کنید یا از گوگل کش استفاده کنید، باید سراغ روشهای دور زدن مستقیم کلودفلر برید. یکی از این روشها استفاده از حل کنندهای چالش های کلودفلر هستش.
برخی از این حل کننده ها در زیر لیست شدن :
- cloudscraper Guide here
- cloudflare-scrape
- CloudflareSolverRe
- Cloudflare-IUAM-Solver
- cloudflare-bypass [Archived]
- CloudflareSolverRe
البته خیلی از موارد بالا، قدیمی شدن ، همچنین کلودفلر هم بروزرسانی هایی رو انجام داده، و ممکنه الان کار نکنن. بهترین ابزاری که الان جوابگو هستش FlareSolverr هستش.
FlareSolverr یه سرور پروکسی هستش که امکان دور زدن Cloudflare و محافظ DDoS-GUARD رو فراهم میکنه. با اجرای FlareSolverr ، یه سرور پروکسی ایجاد میشه و درخواست های شما رو با استفاده از puppeteer و پلاگین stealth به سایتی که پشت کلودفلر هست می فرسته و قبل از اینکه پاسخ و کوکی ها به اسکرپر شما برگرده، چالش کلودفلر حل میکنه و درخواست معتبر میکنه. حالا کاربر میتونه با استفاده از این کوکی ها، در کلاینتهای HTTP معمولی ، برای دور زدن کلودفلر استفاده کنه. برای حل چالش ها هم از Python Selenium با undetected-chromedriver استفاده میکنه.
مزیت این روش نسبت به headless browser اینه که در این روش شما تنها نیاز به بدست آوردن یه کوکی معتبر هستید و بعدش از این کوکی استفاده میکنید.
برای استفاده از این ابزار باید اسکرپر یا برنامه های دیگه رو جوری کانفیگ کنید که درخواستهاشون به سرور FlareSolverr ارسال کنن :
|
1 2 3 4 5 6 7 8 9 10 11 |
import requests post_body = { "cmd": "request.get", "url":"https://cloudflare.com/", "maxTimeout": 60000 } response = requests.post('http://localhost:8191/v1', headers={'Content-Type': 'application/json'}, json=post_body) print(response.json()) |
در نتیجه کوکی و HTML رو در پاسخ دریافت میکنید :
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 |
{ "status": "ok", "message": "Challenge not detected!", "solution": { "url": "https://cloudflare.com/", "status": 200, "cookies": [ { "domain": ".cloudflare.com", "expiry": 1705160731, "httpOnly": false, "name": "datadome", "path": "/", "sameSite": "Lax", "secure": true, "value": "5H6S1eVa4qoqPbzbQxo4fGjFNdeY7ZUE40Qlk0ZQTiLk5b8aqv4nYNE6-JC1MQtUs4k4lBXf-ScmiijLOk1QlolRRVVlUTtc1i_maPBzFSz4AJVtM~_iWqJGNPZpbJge" } ... ], "userAgent": "Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/108.0.0.0 Safari/537.36", "headers": {}, "response": "<html><head>...</head><body>...</body></html>" }, "startTimestamp": 1673459546891, "endTimestamp": 1673459560345, "version": "3.0.2" } |
یه عیبی که این ابزار داره اینه که پاسخ هایی که میگیره قابل اعتماد نیستن و باید خودتون تاییدش کنید. همچنین با توجه به اینکه FlareSolverr برای هر درخواست یه پنجره جدید باز میکنه، بنابراین اگه تعداد درخواستها زیاد بشه، مشکل مموری خواهید داشت و سرور دچار کرش میشه. بنابراین یا باید تعداد درخواستهارو مدیریت کنید یا از یه سروری استفاده کنید که رم بالایی داشته باشه.
یه نکته هم که هست این که، کلودفلر علاوه بر اینکه یسری محاسبات ریاضی و تست جاوااسکریپت روی مرورگر انجام میده، گاهی اوقات مجبور میکنه تا کاربر یه CAPTCHA رو حل کنه. اگرچه FlareSolverr میتونه با استفاده از CAPTCHA solver های شخص ثالث کپچاهارو حل کنه اما به دلیل اینکه کلودفلر از hCAPTCHA استفاده میکنه، بنابراین ابزاری برای دور زدن این کپچا نیستش و باید از روش های مبتنی بر انسان استفاده کنید.
4- اسکرپینگ با Headless Browsers های تقویت شده :
یه روش دیگه برای دور زدن کلودفلر، استفاده از headless browser هستش که شبیه به یه مرورگر واقعی عمل میکنن. از جمله headless browser های قابل استفاده :
Puppeteer : پلاگین stealth برای puppeteer
Playwright : پلاگین stealth برای Playwright
Selenium : یه undetected-chromedriver بهینه شده برای Selenium Chromedriver
Headless browser ها تقریبا 200 نشتی دارن که مشخص میکنه ، این یه مرورگر نرمال نیست . یکی از موارد معروفش navigator.webdriver هستش، در مرورگرهای نرمال مقدار navigator.webdriver برابر false هستش اما این مقدار در Headless browser ها برابر true هستش.
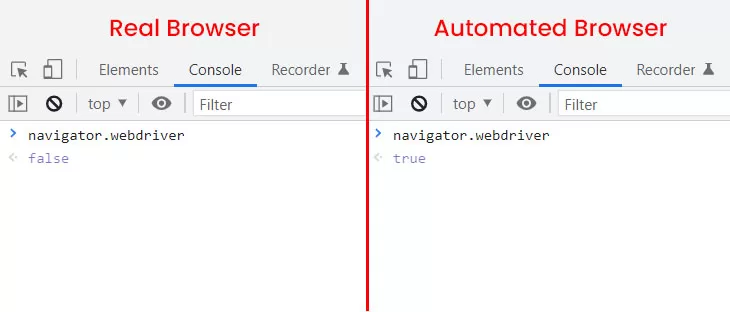
این پلاگین های stealth کاری که میکنن میان و این نشتی ها رو پوشش میدن و میتونن خیلی از سرویس های آنتی بات مانند کلودفلر ، PerimeterX ، Incapsula و DataDome رو بسته به میزان امنیتی که در سایت ارائه شده رو دور بزنن.
البته گفته میشه که این نشتی ها تعدادشون بالاست چون مرورگرها دائما در حال پیشرفت هستن و توسعه دهندگان مرورگرها و شرکتهای آنتی بات علاقه ندارن که خیلیاشون رو افشاء کنن.
یه راه دیگه برای تقویت و ناشناس کردن Headless browser ها، اینه که اونارو همراه با residential proxy یا mobile proxy استفاده کنید. این پروکسی ها معمولا توسط سرویس های آنتی بات، کمتر مسدود میشن و قابلیت اطمینان بالایی دارن.
ایراد این روش هم اینه که ، هزینه به شدت بالا میره. این پروکسی ها معمولا بصورت مصرف پهنای باند براساس گیگابایت شارژ میشن و با توجه به اینکه صفحه ای که توسط headless browser باز میشه بطور متوسط 2 مگابایت مصرف داره، در نتیجه در صورتی که میزان درخواست بالایی داشته باشید، به صرفه شاید نباشه.
در زیر یه مثال از headless browser با یه residential proxy از BrightData با فرض مصرف 2 مگابایت برای هر صفحه آورده شده :
| Pages | Bandwidth | Cost Per GB | Total Cost |
|---|---|---|---|
| 25,000 | 50 GB | $13 | $625 |
| 100,000 | 200 GB | $10 | $2000 |
| 1 Million | 2TB | $8 | $16,000 |
میتونید از این ابزار برای مقایسه پروکسی ها و پیدا کردن یه مورد مطابق با معیارهای خودتون، استفاده کنید.
در ادامه یه مثال با Selenium Undetected ChromeDriver انجام میدیم. در ابتدا نیاز هستش که این ابزار رو نصب کنیم :
|
1 |
pip install undetected-chromedriver |
بعد از نصب ، از اون بعنوان Chromedriver پیش فرض در بات یا اسکرپرمون استفاده میکنیم :
|
1 2 3 4 |
import undetected_chromedriver as uc driver = uc.Chrome() driver.get('https://cloudflare.com/') |
اگه هم بخوایین از پروکسی هایی که نیاز به احرازهویت دارن استفاده کنید، کد به شکل زیر تغییر میکنه :
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
import seleniumwire.undetected_chromedriver as uc ## Chrome Options chrome_options = uc.ChromeOptions() ## Proxy Options proxy_options = { 'proxy': { 'http': 'http://user:pass@ip:port', 'https': 'https://user:pass@ip:port', 'no_proxy': 'localhost,127.0.0.1' } } ## Create Chrome Driver driver = uc.Chrome( options=chrome_options, seleniumwire_options=proxy_options ) driver.get('https://cloudflare.com/') |
برای دریافت جزییات بیشتر در این خصوص ، این راهنما رو ببینید.
5- استفاده از پروکسی های هوشمند با قابلیت دور زدن کلودفلر
یکی از معایبی که Cloudflare Solver و Headless Browsers های متن باز دارن اینه که شرکتهای آنتی بات مانند کلودفلر، میتونن بررسیشون کنن و نحوه دور زدنشون رو بدونن و در نتیجه باگهاشون رو اصلاح کنن.
بنابراین خیلی از روشهای عمومی دور زدن کلودفلر، بعد از مدتی از کار می افتن.
یکی از روشهای دور زدن کلودفلر استفاده از پروکسی های هوشمندی هستش که بصورت خصوصی (close source) روشهای دور زدن رو توسعه و نگهداری میکنن.
استفاده از اینا معمولا قابل اعتمادتره چون برای شرکتهایی مانند کلودفلیر سختتره که براشون اصلاحیه ایجاد کنه و همچنین انگیزه مالی که ارائه دهدنگان این پروکسی دارن، باعث میشه یه قدم جلوتر از شرکتهای آنتی بات باشن.
اغلب ارائه دهدنگان پروکسی هوشمند مانند ScraperAPI و Scrapingbee و Oxylabs و Smartproxy ، امکان دور زدن کلودفلر رو دارن که سطوح و هزینه های مختلفی دارن .
یکی از بهترین گزینه ها، ScrapeOps Proxy Aggregator هستش چون 20 ارائه دهنده پروکسی رو با یه API در اختیارتون قرار میده و هزینه کمتری هم داره.
میتونید با قرار دادن bypass=cloudflare در درخواست APIتون، Cloudflare Bypass رو فعال کنید و ScrapeOps proxy از ارزانترین و بهترین روش های دور زدن کلودفلر برای دامنه مورد نظر شما استفاده میکنه. در حقیقت شما دغدغه دور زدن کلودفلر ندارید.
|
1 2 3 4 5 6 7 8 9 10 11 12 |
import requests response = requests.get( url='https://proxy.scrapeops.io/v1/', params={ 'api_key': 'YOUR_API_KEY', 'url': 'http://example.com/', ## Cloudflare protected website 'bypass': 'cloudflare', }, ) print('Body: ', response.content) |
میتونید اینجا یه اکانت با اعتبار 1000 API بصورت رایگان ایجاد و استفاده کنید.
یکی از مزیت های این روش اینه که میتونید با خیال راحت ، حتی از طریق کلاینتهای معمول HTTP ، هم در برنامه هاتون استفاده کنید و نگرانی در خصوص روشهای دور زدن کلودفلر نداشته باشید چون این سرویس همه روشها رو خودش اون پشت انجام میدن.
6- مهندسی معکوس سیستم حفاظتی آنتی بات کلودفلر :
آخرین و البته سختترین روش برای دور زدن آنتی بات کلودفلر، مهندسی معکوس اون و ایجاد یه بایپسر برای دور زدن اون هستش. این رویکرد همون کاری هستش که پروکسی های هوشمند انجام میدن اما برای افرادی که دانش کمی دارن، میتونه سخت باشه.
شما باید در سیستمی که درک اون عمدا از بیرون سخت شده ،عمیق بشید و تکنیکهای مختلف دور زدن رو روش تست کنید. همچنین نیاز دارید که این سیستم رو باتوجه به اینکه کلودفلر در حال پیشرفت هستش، حفظ کنید.
بنابراین اگه علاقمند به حل چالش های مهندسی معکوس یه سیستم پیچیده آنتی بات هستید یا فکر میکنید این روش از دید اقتصادی ، مقرون به صرفه هست، از این رویکرد استفاده کنید.
وقتی گفته میشه که میخواییم کلودفلر دور بزنیم، در حقیقت میخواییم Bot Manager که بخشی از WAF کلودفلر هستش رو دور بزنیم. هدف این سیستم کاهش حملات باتهای مخرب، بدون تاثیر روی کاربر واقعی هستش.
سیستم تشخیص بات کلودفلر به دو قسمت تقسیم میشه :
- تکنیکهای تشخیص سمت سرور: روشهایی که برای شناسایی باتها در سمت سرور مورد استفاده قرار میگیرن.
- تکنیکهای تشخیص سمت کاربر: روشهایی که برای شناسایی باتها در مرورگر کاربران مورد استفاده قرار میگیرن.
برای دور زدن کلودفلر، باید هر دو روش رو دور بزنید.
6-1- روشهای دور زدن تکنیکهای تشخیص سمت سرور:
در زیر برخی تکنیکهای تشخیص سمت سرور و روش دور زدن اونها رو مشاهده میکنید :
6-1-1-وضعیت کیفیت پروکسی:
یکی از اساسی ترین کارهایی که کلودفلر انجام میده، محاسبه IP address reputation score ، آی پی ارسال کننده درخواست هستش.
IP address reputation score یه عدد بین 0 تا 100 هستش که قابلیت اعتماد IP رو مشخص میکنه. عوامل متعددی میتونه روی این عدد تاثیر بزاره از جمله : بعنوان بخشی از یه شبکه بات باشید، مکان شما، ISP و سابقه اعتبار. مثلا از این امتیاز سرورهای ایمیل برای شناسایی و مسدود کردن هرزنامه ها استفاده میکنن.
برای مشاهده این امتیاز میتونید از این سایت استفاده کنید.
برای دور زدن این تکنیک تشخیص، میتونید از پروکسی های residential/mobile روی پروکسی های دیتاسنتری و هر نوع VPN دیگه استفاده کنید. البته اگه پروکسی های دیتاسنتری کیفیت خوبی داشته باشن هم میشه با اونا دور زد.
6-1-2- هدر های HTTP مرورگر:
کلودفلر هدرهای HTTP درخواست رو بررسی و آنالیز میکنه و با یه دیتابیس از هدرهای شناخته شده مرتبط با مرورگر، ارزیابی میکنه.
اکثر کلاینت های HTTP ، همون هدرهایی که بصورت پیش فرض ست شدن رو ارسال میکنن که در نتیجه قابل شناسایی هستن. بنابراین باید این هدرهارو کنار بزارید و از هدرهایی استفاده کنید که میخوایید ، رفتار اون مرورگر رو تقلید کنید. برای این کار میتونید از این راهنما یا APIهای رایگان Fake Browser Headers API استفاده کنید.
6-1-3- شناسایی TLS و HTTP/2 :
هر کلاینت HTTP یه اثر انگشت (fingerprint) خاصی برای TLS و HTTP/2 ایجاد میکنه. کلودفلر با مقایسه این اثر انگشت و هدرهای مرورگر، بررسی میکنه که آیا این دو مورد با هم تطابق دارن یا نه.
نکته ای که هست اینه که جعل اثرانگشت خیلی سختتر از هدرهای مرورگر هستش. برای این کار باید پکتهایی که از مرورگر استخراج میشن رو انالیز کنید و اثرانگشت خاص اون مرورگر رو بدست بیارید و اونارو در درخواستی که ارسال میکنید، اصلاح کنید.
یه نکته دیگه اینکه خیلی از کلاینتهای HTTP مانند Python Requests، اجازه تغییر و دستکاری اثرانگشت TLS و HTTP/2 رو نمیدن برای این کار میتونید از کلاینتهایی مانند Golang HTTP یا Got که امکان کنترل سطح پایینی از درخواست برای جعل اثرانگشت میدن، استفاده کنید.
کتابخونه هایی مانند CycleTLS و Got Scraping و utls امکان جعل اثرانگشت TLS/JA3 در GO و جاوااسکریپت رو فراهم میکنن.
این موضوع پیچیده ای هستش و میتونید از منابع زیر برای درک فرایند اثرانگشت استفاده کنید :
- Passive Fingerprinting of HTTP/2 Clients (Akami White Paper, 2017)
- What happens in a TLS handshake?
- TLS Fingerprinting with JA3 and JA3S
نکته ی مهمی که وجود داره اینه که ،باید هدرها و اثرانگشت درخواست ارسالی با هم تطابق داشته باشن.
تکنیکهای تشخیص سمت سرور، اولین خط دفاعی کلودفلر هستن، اگه اینارو نتونید دور بزنید، کلودفلر اونارو مسدود میکنه یا شمارو به چالش میکشه.
تکنیکهای تشخیص سمت سرور یه امتیاز ریسک به درخواست شما میدن که کلودفلر از اون برای چالش های سمت کاربر استفاده میکنه. هدف شما در دور زدن کلودفلر اینه که بتونید حداقل امتیاز ریسک رو بدست بیارید. در غیر صورت بسته به سطح حفاظتی که ادمین سایت برای سایتش در نظر گرفته، کلودفلر میتونه چالشهایی سمت کاربر مانند کپچا یا مواردی در پس زمینه اجرا کنه.
6-2- روشهای دور زدن تکنیکهای تشخیص سمت کاربر:
خب فرض میکنیم که شما سیستمی رو توسعه دادید که تکنیکهای سمت سرور دور میزنه. حالا باید روی تکنیکهای دور زدن تشخیص سمت کاربر کار کنید.
تکنیکهای سمت کاربر زمانی اجرا میشن که شما با صفحه امنیتی کلودفلر مواجه میشید:
وقتی شما یا اسکریپت شما در حال بازدید از یه سایتی برای اولین بار باشید، کلودفلر این صفحه رو نشون میده و یسری چالش رو حل میکنه تا مطمئن بشه که شما ربات نیستید.
اگه ربات تشخیص داده بشید یه خطای 403 Access Denied / Forbidden رو مشاهده میکنید.
امتیاز ریسکی که شما از تکنیکهای تشخیص سمت سرور بدست آورید، روی این چالشها تاثیر میزاره مثلا ممکنه از شما درخواست بشه که یه کپچایی رو حل کنید.
سه رویکرد کلی برای دور زدن این چالش ها وجود داره :
- استفاده از مرورگر خودکار: استفاده از مرورگرهای تقویت شده که امکان حل چالش های جاوااسکریپت کلودفلر رو فراهم میکنن.
- شبیه سازی مرورگر در یه سندباکس: شبیه سازی یه مرورگر سندباکسی با استفاده از کتابخونه هایی مانند JSDOM که منابع کمتری نیاز دارن و کنترل دقیقی در اختیار شما قرار میدن.
- ایجاد یه الگوریتم حل کننده چالش ها: الگوریتمی بسازید که چالش هارو بدون مرورگر حل کنه. این سختترین رویکرد هستش چون نیاز دارید تا تمام تکنیکهای سمت کاربر رو درک کنید، اسکریپتهای چالش های جاوااسکریپت کلودفلر رو deobfuscate کنید و در نهایت یه الگوریتم برای حل اونا بسازید.
در زیر تکنیکهای اصلی تشخیص بات سمت کاربر که شما نیاز به دور زدنشون دارید رو بررسی میکنیم :
6-2-1 بررسی API های وب مرورگر :
مرورگرهای مدرن، یسری API دارن که به توسعه دهندگان اجازه میدن تا برنامه هایی رو توسعه بدن که بتونن با مرورگرها تعامل داشته باشن. وقتی کلودفلر در یه مرورگری باز میشه، کلود فلر به همه این APIها دسترسی داره. در نتیجه میتونه از اونا برای شناسایی کامل محیط مرورگر استفاده کنه. برای مثال کلودفلر میتونه کوئری های زیر رو داشته باشه:
- APIهای مخصوص مرورگر: یسری API مختص مرورگر خاصی هستن ، مثلا window.chrome مخصوص کروم هستش. بنابراین باید هدر، اثرانگشت و این APIها با هم همخونی داشته باشن در غیر اینصورت، کلودفلر تشخیص میده که شما جعلی هستید.
- APIهای مرورگرهای خودکار: مرورگرهای خودکار مانند Selenium هم یسری API مخصوص به خودشون دارن مانند window.document.__selenium_unwrapped . بنابراین اگه کلودفلر این API رو ببینه متوجه میشه شما جعلی هستید.
- APIهای شبیه ساز مرورگر های سندباکسی: مرورگرهای سندباکسی مانند JSDOM که در NodeJs اجرا میشه یه شی پردازشی دارن که فقط در NodeJs وجود داره. بنابراین کلودفلر با مشاهده اون میتونه تشخیص بده که شما جعلی هستید.
- APIهای محیطی: اگه user-agent شما مک یا ویندوز ست شده باشه اما مقدار navigator.platform روی Linux x86_64 باشه، کلودفلر به درخواست شما مشکوک میشه.
اگه از یه مرورگر تقویت شده استفاده کنید، خیلی از این نشتها دور زده میشن اما شما باید بررسی کنید تا مواردی مانند هدرها و اثر انگشت و APIها با هم همخوانی داشته باشن.
6-2-2-انگشت نگاری بوم (Canvas Fingerprinting):
Canvas Fingerprinting تکنیکی هستش که در اون کلودفلر ، نوع دستگاه مورد استفاده رو براساس ترکیبی از مرورگر ، سیستم عامل و سخت افزار گرافیکی سیستم طبقه بندی میکنه.
کلودفلر برای ترسیم این اثر انگشت از تکنیک Picasso Fingerprinting گوگل ، استفاده میکنه.
Canvas Fingerprinting یکی از رایج ترین تکنیک های انگشت نگاری مرورگر هستش و از API HTML5 برای ترسیم گرافیک و انیمیشن در یک صفحه با جاوا اسکریپت استفاده میکنه، بعدش می تونه از اونا برای تولید اثر انگشت دستگاه استفاده کنه.
برای مشاهده این اثرانگشت میتونید از BrowserLeaks Live Demo استفاده کنید.
کلودفلر مجموعه داده های زیادی از این اثرانگشت و user-agent مرتبطش رو نگه میداره و بررسیشون میکنه. بنابراین اگه یه درخواستی می فرستید که در هدرش ادعا میکنید فایرفاکس روی ویندوز هستید، اما Canvas Fingerprinting شما نشون دهنده کروم روی لینوکسه، کلودفلر به شما مشکوک میشه.
6-2-3-رهگیری رویداد:
اگه برای استخراج داده از یه سایتی نیاز به حرکت یا تعامل در صفحه داشته باشید باید رهگیرهای رویداد کلودفلر رو هم دور بزنید.
کلودفلر یسری event listener به صفحه اضافه میکنه تا فعالیت کاربر مانند حرکت ماوس، کلیک ها و کلیدهای فشرده شده رو مونیتور کنه. بنابراین اگه یه اسکرپر دارید که داده هایی از سایت در میاره اما ماوس تکون نمیخوره، کلودفلر بهش مشکوک میشه.
6-2-4- حل CAPTCHA :
حل چالش های CAPTCHA سختترین نوع چالش های ضد بات کلودفلر هستش.
کلودفلر در موارد زیر کاربر رو مجبور به حل چالش کپچا میکنه :
- امتیاز ریسک بالایی در تکنیکهای تشخیص سمت سرور بدست بیارید
- سایت از نظر امنیتی جوری پیکربندی شده که گاهی یا همیشه یه چالش کپچا رو باید حل کنید.
خوشبختانه خیلی از سایتها دوست ندارن چالش کپچارو نشون بدن چون به تجربه کاربری آسیب میزنه.
اگه در مواردی با سایتی روبرو شدید که چالش کپچا رو برای همیشه تنظیم کرده باشه، باید از سرویس های حل کننده های کپچای مبتنی بر انسان برای حل چالش های hCaptcha استفاده کنید. چون حل کننده خودکار کپچا نمیتونن چالش های hCaptcha رو حل کنن. این روش البته کند و هزینه بر هستش.
در غیر اینصورت باید برنامه اتون رو جوری پیکربندی کنید که امتیاز ریسک رو به حداقل برسونید تا با کپچا روبرو نشید.
دور زدن سطح پایین:
در حالت کلی مهندسی معکوس و توسعه یه بایپس سطح پایین که از headless browser استفاده نمیکنه ، کار سخت و چالش برانگیزیه، چون باید:
- درخواستهای شبکه کلودفلر وقتی صفحه Waiting Room لوود میشه رو رهگیری کنید
- کد کلودفلر رو Deobfuscate کنید
- چالش های جاوااسکریپت در کدهای مبهم شده رو دیکریپت کنید
- چالش های جاوااسکریپت در کدهای Deobfuscate رو درک کنید
- چالش های جاوااسکریپت رو حل کنید و نتیجه درست برگردونید
در زیر قسمتی از کدهای Deobfuscate شده کلودفلر برای بررسی APIهای مرورگر رو مشاهده میکنید :
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
function _0x15ee4f(_0x4daef8) { return { /* .. */ wb: !(!_0x4daef8.navigator || !_0x4daef8.navigator.webdriver), wp: !(!_0x4daef8.callPhantom && !_0x4daef8._phantom), wn: !!_0x4daef8.__nightmare, ch: !!_0x4daef8.chrome, ws: !!( _0x4daef8.document.__selenium_unwrapped || _0x4daef8.document.__webdriver_evaluate || _0x4daef8.document.__driver_evaluate ), wd: !(!_0x4daef8.domAutomation && !_0x4daef8.domAutomationController), }; } |
راهنمایی های بیشتر برای Web Scraping :
وقتی نوبت به دور زدن کلودفلر میشه گزینه های مختلفی رو دارید که هر کدوم ویژگی ها و معایب خاص خودشون رو دارن. اگه علاقمند به Web Scraping برخی سایتها دارید میتونید راهنماهای زیر مشاهده کنید :
اگه هم نیاز به اطلاعات کلی در خصوص Web Scraping دارید میتونید کتاب The Web Scraping Playbook رو بخونید و یا مقاله های زیر رو بخونید :