هفته های پیش بود که گوگل یه بروزرسانی برای کروم منتشر و یه آسیب پذیری در کتابخونه WebP رو در اون اصلاح کرد. آسیب پذیری توسط تیم SEAR اپل کشف شده بود و شناسه CVE-2023-4863 بهش اختصاص دادن و یه آسیب پذیری از نوع Heap buffer overflow بود. نکته بد ماجرا این بود که آسیب پذیری زیرودی بود و گوگل اعلام کرد که یه اکسپلویت برای این آسیب پذیری توسعه داده شده.
در این پست به بررسی و آنالیز و ابعاد این آسیب پذیری پرداختیم.
مقدمه :
بعد از انتشار بروزرسانی امنیتی کروم، محققای امنیتی شروع به بررسی این کردن که آیا بین CVE-2023-4863 و آسیب پذیری قبلی اپل، CVE-2023-41064 ارتباطی وجود داره یا نه.
اوایل سپتامبر محققای Citizen Lab رفتار مشکوکی رو در آیفون یه فرد شاغل در یه سازمان مدنی در واشنگتن مشاهده کردن و اونو به اکسپلویت زیروکلیک برای iMessage نسبت دادن که برای استقرار جاسوس افزار پگاسوس از NSO group استفاده میشد و این یافته اشون رو به اپل گزارش کردن.
اپل 7 سپتامبر یه بروزرسانی برای اصلاح دو CVE شناسایی شده توسط Citizen Lab منتشر کرد و در گزارششون عنوان کرده بودن که این آسیب پذیری ها در حملاتی مورد اکسپلویت قرار گرفتن.
محققای Citizen Lab ،این حمله رو BLASTPASS نامیدن، چون مهاجم تونسته بود یه راه هوشمندانه برای دور زدن سندباکس iMessage ، یعنی BlastDoor پیدا کنه.
جزییات زیادی در خصوص این حمله در دسترس نیست اما مهاجم با قرار دادن تصویر مخرب ، در یه پیوست PassKit ، باعث پردازش تصویر مخرب در یه پروسس دیگه و بدون سندباکس میشده. اینا اطلاعاتیه که در خصوص آسیب پذیری CVE-2023-41061 داریم.
اما برای اینکه این مورد اتفاق بیافته ، نیاز به یه اکسپلویت داریم که اپل اونو با CVE-2023-41064 مشخص کرد که یه آسیب پذیری buffer overflow در ImageIO هستش.
ImageIO یه چارچوب تجزیه عکس در اپل هستش. یسری بایت رو میگیره و تلاش میکنه تا بایت هارو با یه image decoder مناسب ، تطبیق بده. فرمت های مختلفی رو پشتیبانی میکنه و یه منطقه تحقیقاتی برای محققین امنیتی بوده و هستش. جزییات زیادی در خصوص این آسیب پذیری موجود نبود و مشخص نبود که اکسپلویت روی چه فرمتی اتفاق می افته.
اما نکته ای که وجود داره اینه که ، ImageIO اخیرا شروع به پشتیبانی از فایلهای WebP کرده و محققای اپل 6 سپتامبر، یه گزارش آسیب پذیری برای WebP در کروم برای گوگل ارسال کردن. گوگل بعد از 5 روز این آسیب پذیری رو اصلاح کرد و عنوان کرده بود که این آسیب پذیری مورد اکسپلویت قرار گرفته.
با این اوصاف میشه نتیجه گرفت که آسیب پذیری CVE-2023-41064 و CVE-2023-4863 در حقیقت یه باگ (WebP 0day) هستن.
آسیب پذیری CVE-2023-4863 اولش همه فکر میکردن فقط کروم رو تحت تاثیر قرار میده و یه آسیب پذیری از نوع heap buffer overflow در WebP هستش.مهاجم با یه صفحه HTML مخرب ، میتونست out-of-bounds write داشته باشه.
با بررسی که کردن متوجه شدن که این آسیب پذیری در کتابخونه WebP Codec (libwebp) هستش. وقتی پای این کتابخونه وسط اومد، متوجه شدن که مرورگرها و برنامه های زیادی رو میتونه تحت تاثیر قرار بده. مثلا این کتابخونه در Chromium و مرورگرهای دیگه ای مثله فایرفاکس و همچنین مولفه های مبتنی بر Chromium مانند Electron تاثیر میزاره که خود Electron در برنامه های سمت کلاینت زیادی مانند سیگنال ، تلگرام و Slack استفاده میشه.
در ادامه اومدن شناسه CVE-2023-5129 رو به آسیب پذیری خود WebP اختصاص بدن، اما Mitre به دلیل تکراری بودن اونو رد کرد و بنابراین این آسیب پذیری با همون شناسه CVE-2023-4863 بین محققا استفاده میشه.
آسیب پذیری روی نسخه های 0.5.0 تا 1.3.1 در WebP رخ میده و نسخه 1.3.2 نسخه اصلاح شده هستش. محصولات زیر تحت تاثیر این آسیب پذیری هستن :
| Category | Products |
|---|---|
| Web Browsers | Beaker (web browser), GNOME Web, Google Chrome, Midori, Mozilla Firefox, OhHai Browser, Pale Moon, Safari, SEOBrowse |
| Social Media | Discord, Facebook, Instagram, Linked, ModernDeck for Twitter, Pinterest, Reddit, SpinShare Client, Telegram, Twitter, WhatsApp, Yammer |
| Operating Systems | Android, Windows |
| Video Platforms | Lbry, Twitch, Vimeo, YouTube, YTMDesktop App |
| Graphics Software | Aseprite, GIMP, Graphic Converter, ImageMagick, Paint.NET, Photoshop, Photoshop and Picasa, Pixelmator, XnView |
| Cloud Storage | Amazon Photos, Dropbox, Google Drive, Google Photos |
| Ecommerce | Amazon, Ebay, Etsy, Shopify, WooCommerce |
| CMS | Drupal, Joomla, MediaWiki, WordPress |
| Email Services | Gmail |
| Forum Software | PHPBB, vBulletin, XenForo |
| Photo Editing | GDAL, GIMP, Graphic Converter, ImageMagick, Paint.NET, Photoshop, Photoshop and Picasa, Pixelmator, XnView |
| Game Engines | Godot Engine, Unreal Engine, Unity |
| Desktop Software | 1Password, Basecamp 3, Bitwarden, Blender, Cryptocat (discontinued), Discord, Discord RPC Maker, Electron App Store (Unofficial), Etcher, FastPictureViewer, Fifo FileCtor, Gitify, GitHub Desktop, GitKraken, Gnome Web, healthi, Inboxer, Joplin, Keybase, LibreOffice, Light Table, Logitech Options +, LosslessCut, Mattermost, Microsoft Office 2010, Microsoft Teams, Motrix, Museeks, Music Player, Obsidian, QQ (for macOS), Rambox, Signal, Skype, Slack, Spotify, Symphony Chat, Tabby, Termius, TIDAL, VLC Media Player, Visual Studio Code, WebTorrent, Windows Photo Viewer, Wire, Youtube Music for Desktop |
| Mobile Apps | Lyft, Telegram Messenger, Uber |
| Web Servers | Apache, IIS, nginx |
| Developer Tools | Advanced REST Client, Aeon, Antares, Appium Desktop, Barklarm, Believers Sword, Blockbench, BoxHero, Brim, Buttercup, Camunda Modeler, Cider, Clovery, Codex, Colorpicker, Cozy Desktop, CryptoARM GOST, Dat, DECK, DeckMaster, Deskfiler, Dict, Django, Doki Doki Mod Manager, Dopamine, DropPoint, Dusk Player, EBTCalc, ElectroCRUD, Electron App Store (Unofficial), Erin, ETCD Manager, Etcher, ExifCleaner, Fifo FileCtor, Fishing Funds, FLB Music, Flask, Frame, Gaucho, Gitify, gSubs, healthi, HexoClient, ImageShrinker, Inboxer, Invizi, itch, Jasper, Juggernaut, Kahla, Kap, KeeWeb, Knowte, Kube Dev Dashboard, Kube Forwarder, Laravel, Laravel Kit, Last Hit, LBRY Desktop, Lepton linked, Lisk Hub, lsdeer, Mailspring, Markdownify, massCode, mdp, mediaChips, Metronome Wallet, Mini Diary, MJML App, Monokle, monolith code, MongoDB Compass, MoviePrint, Mullvad, Netron, Network Status Check, nteract, nuclear, OhHai Browser, Oversetter, P3X Redis UI, PanWriter, passky, Patchwork, Pencil, Picturama, PiTV, poi, Pomotroid, PreMiD, PrettyEarth, Primate Puppetry, Qawl, Quark, Quba E-Invoice Viewer, QuickRedis, R6RC, Rainbow Board, Rambox, Rebaslight, Recode Converter, Redis GUI (unofficial), RenderTune, React, Responsivize, Ride Receipts, Scratch For Discord, SeaPig, Serina, Silex website builder, SimpleInstaBot, Singlebox, Snippet Store, Socially, Soundnode, SpaceEye, SpinShare Client, Sqlectron, sqlui-native, Standard Notes, Standup Picker, Streamlabs OBS, Sturdy, Subtitler, Super Productivity, Switch, TagSpaces, Taskana, TextureLab, Thorium Reader, Time Series Admin, To Do, todometer, Transee, Translatium, Tropy, Tusk, Twinkle Tray, U Stair, Unfx Proxy Checker, Upcount, Vue.js, WebKitty, WizardMirror, wnr, yana, Zap |
| Major Companies | Facebook, Google, Slack, Wikimedia, WordPress.com |
| Other Programs/Scripts | Display-dj, FFmpeg, GDAL, music-player, Musify, Notion, photoline, Picasa, React, Signal, Sumatra PDF, Vue.js |
آسیب پذیری همچنین روی برنامه هایی که از کتابخونه پایتونی Pillow استفاده میکنن هم تاثیر میزاره. نکته بد ماجرا اینجاست که برخی از این برنامه ها و مولفه های نرم افزاری در ایمیج های کانتینرها قرار میگیرن.
اندروید هم دارای ویژگی بنام BitmapFactory هستش که کار دیکد تصاویر رو انجام میده و از libweb هم پشتیبانی میکنه. اندروید در بروزرسانی اکتبر این آسیب پذیری رو برای اندروید 11 به بالا اصلاح کرده.
این نکته رو در نظر بگیرید که این کتابخونه در 99درصد مواقع بطور غیرمستقیم و بهمراه برنامه های دیگه نصب و مورد استفاده قرار میگیره. بنابراین اینجا دو تا نکته وجود داره، یکی اینکه ممکنه اون برنامه نسخه اصلاح شده رو استفاده نکنه و در نتیجه تحت تاثیر آسیب پذیری باشید. نکته دوم هم اینکه ممکنه هکرها در قالب یه برنامه، از نسخه آسیب پذیر استفاده کنن و اکسپلویت رو اعمال کنن.
بررسی باگ WebP 0day :
محققا با بررسی بولتن امنیتی کروم و کتابخونه libwebp ، به گزارش و اصلاح باگ 902bc9190331343b2017211debcec8d2ab87e17a رسیدن. این اصلاحیه 7 سپتامبر منتشر شده و مطابق با CVE-2023-4863 هستش. با بررسی اولیه اصلاحیه میشه نکات زیر رو استخراج کرد :
- آسیب پذیری در پشتیبانی lossless compression یا فشرده سازی بدون اتلاف ، در WebP رخ میده که بهش VP8L هم میگن. فرمتهایی مانند PNG ،GIF و WebP از این فشرده سازی استفاده میکنن، البته میتونید مثلا jpg رو تبدیل به WebP کنید.
- این نوع فشرده سازی بدون کاهش کیفیت تصویر رخ میده و برای همین بهش بدون اتلاف میگن. فرمت تصویر بدون اتلاف (lossless) ، میتونه پیکسلهارو با دقت 100 درصدی ذخیره و بازیابی کنه، یعنی تصویر با دقت کامل نمایش داده میشه. برای رسیدن به این هدف ، WebP از الگوریتم Huffman coding استفاده میکنه.
- اگرچه Huffman coding از نظر مفهومی براساس ساختار داده درختی هستش، اما یسری پیاده سازی های مدرن ازش انجام شده که امکان استفاده از جدول رو هم میده. اصلاحیه نشون میده که وقتی یه تصویر مخرب دیکد میشه، امکان سرریز جدول هافمن وجود داره.
بطور کلی ، نسخه های آسیب پذیر، برای تخصیص حافظه از اندازه های بافر از پیش محاسبه شده که در یه جدول ثابت هستن، استفاده میکنن و جدول هافمن رو مستقیما در اون میسازه. اما نسخه های اصلاح شده، در ابتدا اندازه کل جدول خروجی رو محاسبه میکنن، اما جدول رو در بافر نمی نویسن. اگه اندازه کل بزرگتر از اندازه بافر از پیش محاسبه شده باشه، بنابراین یه تخصیص بزرگتر انجام میشه.
اینا اطلاعات مفید هستن، اما به ما اطلاعاتی نمیدن که بتونیم یه فایل نمونه بسازیم و سرریز رو انجام بدیم. بنابراین برای این کار نیاز هستش که بدونیم کد چطوری کار میکنه و اصلا چرا اندازه بافر از پیش محاسبه شده کافی نبوده. یا برعکسش بدونیم کد آسیب پذیر دقیقا چیکار میکنه؟
قبل از اینکه سراغ ساخت نمونه بریم تا اکسپلویت رو پیاده سازی کنیم، یه نگاهی به کد هافمن میندازیم.
کد هافمن:
فرض کنید میخواییم یه متنی رو ارسال کنیم، که شامل حروف مختلف هستش. قطعا یکی از دغدغه های ما اینکه پیام ارسالی ما حجم کمتری رو اشغال کنه تا هزینه ارسال و نگهداریش کمتر باشه، یا بقولی فشرده باشه. برای این کار راهکارهای مختلفی وجود داره که یکیش کد هافمن هستش.
کلا اساس کد هافمن اینجوریه که ،مثلا یه متنی رو تبدیل به دنباله ای از بیت ها میکنه بطوریکه، کاراکترهایی که کمترین تکرار رو دارن، بیشترین دنباله بیت رو دارن و کاراکترهایی که بیشترین تکرار رو دارن کمترین دنباله بیت رو شامل میشن. در نتیجه اینجوری مثلا یه متن رو میتونه فشرده کنه. در حقیقت یه طول متغیر به کاراکترها میده تا اونایی که بیشتر تکرار میشن حجم کمتری رو اشغال کنن .
الگوریتم کلیش اینجوریه که :
- کاراکترهارو براساس تعداد تکرارهاشون (فراوانی) بدست میاره.
- این کاراکترهارو براساس تعداد فراوانی بصورت صعودی مرتب میکنه و در یه صف قرار میده.
- برای هر کاراکتر بصورت صعودی، یه گره میکشه .
- حالا کاراکترهایی که فراوانی کمتری دارن باهم جمع میشن و حاصل دوباره در صف مرتب میشه.
- این جمع شدن تا زمانی ادامه پیدا میکنه که دیگه موردی برای ترکیب نباشه.
- در نهایت ما یه درخت داریم که از برگها به ریشه رسیدیم.
- این درخت رو از ریشه به سمت برگها با 0و1 کدگذاری میکنیم. با این قانون که یال سمت چپ 0 و یال سمت راست 1 باشه.
- حالا از ریشه به برگها حرکت میکنیم و کد اختصاصی هر برگ رو بدست میاریم.
یه مثال بزنیم تا قضیه جا بیافته. مثلا فرض کنید که به ما یه متنی رو دادن که شامل کاراکترهای زیر هستش و گفتن که این متن رو ارسال کنید.
| حروف | تکرار |
| a | 100 |
| b | 220 |
| c | 50 |
| d | 280 |
| e | 323 |
ما برای ارسال راحتتر ، از کد هافمن استفاده میکنیم.
مرحله اول رو که داریم. تعداد تکرار هر حرف رو در جدول بالا مشخص کردیم.
در قدم دوم، اینارو بصورت صعودی مرتب میکنیم و در یه صف قرار میدیم
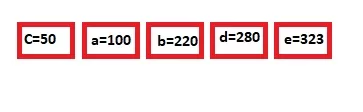
این کاراکترها رو بصورت گره در نظر میگیریم و بعدش دو تای اولی که کمتر تکرار شدن رو با هم جمع میکنیم و نتیجه در صف در جای مناسب قرار میدیم (صف همیشه صعودیه):
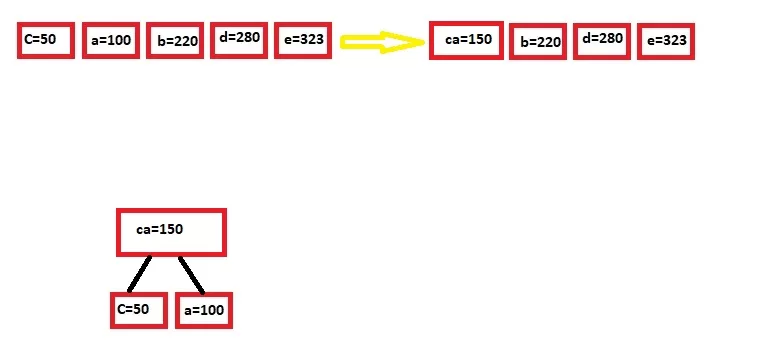
خب این مراحل رو تکرار میکنیم تا عنصری برای ترکیب باقی نمونه:
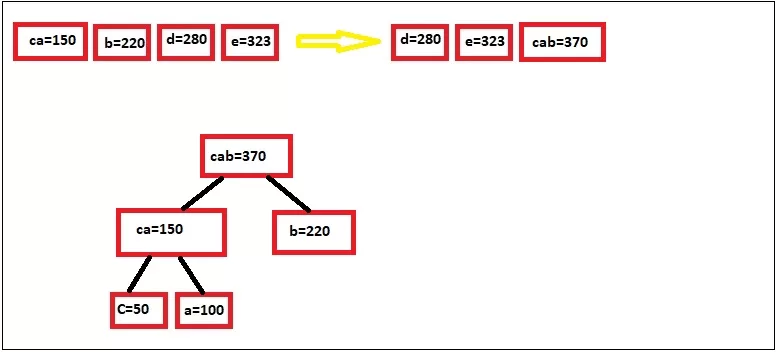
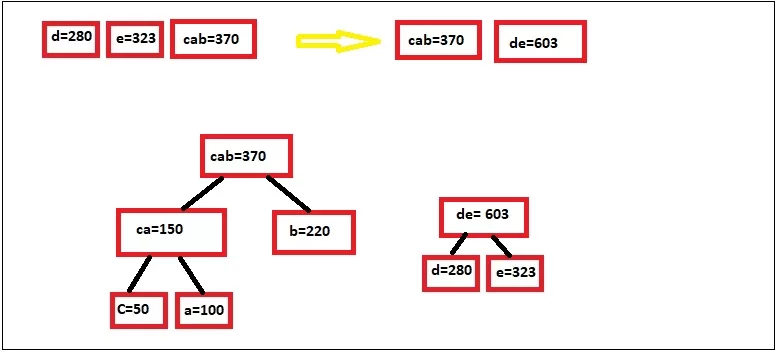
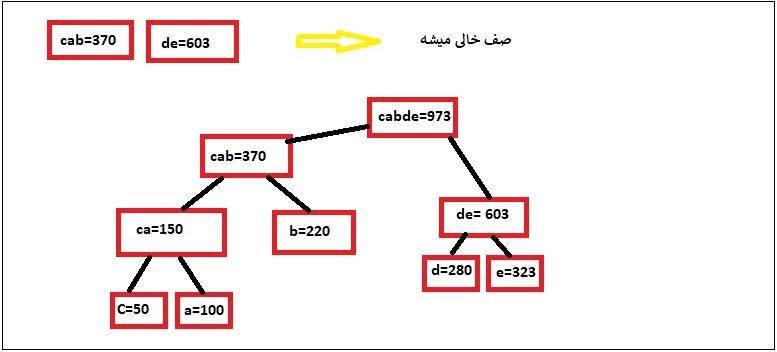
خب الان ما به انتهای صف رسیدیم و در این مرحله برای یالهای سمت چپ عدد 0 و یالهای سمت راست عدد 1 رو میدیم:
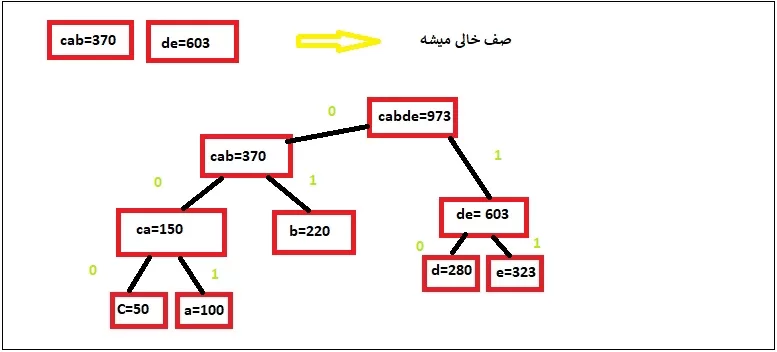
مطابق جدول بالا ، کاراکترهای ما کدهای زیر میگیرن :
| حروف | تعداد تکرار | کد هافمن |
| c | 50 | 000 |
| a | 100 | 001 |
| b | 220 | 01 |
| d | 280 | 10 |
| e | 323 | 11 |
همونطور که مشاهده میکنید، کاراکترها دارای کدهای منحصر به فرد هست و کاراکترهایی که کمترین تکرار رو دارن بیشترین دنباله بیت ( مثلا c سه بیت گرفته، سه تا 0) و کاراکترهای با بیشترین تکرار کمترین دنباله بیت ( مثلا e دو بیت رو اشغال کرده). در حقیقت بجای اینکه مثلا c رو ارسال کنیم 000 می فرستیم.
فرض کنید میخواییم پیام baba ab dad رو ارسال کنیم . بنابراین توالی کد ما اینجوری میشه (از spaceها صرفنظر شده) :
| d | a | d | b | a | a | b | a | b |
| 10 | 001 | 10 | 01 | 001 | 001 | 01 | 001 | 01 |
| 0100101001001011000110 | ||||||||
خب خروجی ارسالی 0100101001001011000110 میشه که 22 بیت سایزشه. حالا فرض کنید از این کد استفاده نمی کردیم: (سطر دوم معادل باینری کدهای اسکیه، چون ما تو سیستم دیجیتال فقط 0و1 داریم)
| d | a | d | b | a | a | b | a | b |
| 1100100 | 1100001 | 1100100 | 1100010 | 1100001 | 1100001 | 1100010 | 1100001 | 1100010 |
| 110001011000011100010110000111000011100010110010011000011100100 | ||||||||
با توجه به جدول بالا، بدون کد هافمن ، 63 بیت رو باید انتقال بدیم که تقریبا سه برابر کد هافمن هستش. پس اینجوری میشه فشرده سازی رو انجام داد.
تنها یه مورد میمونه اونم اینکه ما این پیام رو ارسال میکنیم ، اون طرف چطوری دیکد میکنه؟ طرف مقابل اون درخت آخری رو داره و براساس اون دیکد میکنه. مثلا اگه دنباله 01001 رو ارسال کنیم، طبق درخت اگه حرکت کنیم، فقط از ریشه باید به برگ ها برسیم که کاراکترهای ماست. 01 نشون دهنده b و 001 تنها نشون دهنده a هستش و …
آنالیز فنی آسیب پذیری WebP 0day :
برای این که بتونیم یه نموه یا بقولی PoC توسعه بدیم باید بدونیم کد چطوری کار میکنه و اصلا چرا اندازه بافر از پیش محاسبه شده کافی نیست. یا برعکسش بدونیم کد آسیب پذیر دقیقا چیکار میکنه؟
وقتی یه تصویر WebP به شکل lossless فشرده میشه، یه تحلیل فراوانی (frequency analysis) از پیکسل های ورودی انجام میگیره. ایده اصلی اینه که مقادیر ورودی که بیشتر اتفاق می افتن رو میشه بصورت دنباله کوتاهتری از بیت های خروجی نسبت داد و مقادیری که کمتر اتفاق می افتن، به دنباله طولانی تری از بیت های خروجی نسبت داد. نکته اصلی اینه که بیت های خروجی هوشمندانه انتخاب بشن تا رمزگشا بتونه همیشه طول اون دنباله مشخص رو محاسبه کنه. یعنی همیشه میتونه بین یه کد 2 بیتی و یه کد 3 بیتی و … تفکیک بشه و بنابراین دیکدر همیشه میدونه چند بیت استفاده کنه.
برای رسیدن به این هدف ، تصویر فشرده شده باید شامل تمام اطلاعات آماری در خصوص فراوانی و تخصیص کدها باشه تا دیکدر بتونه همون نگاشت بین کدها و مقادیر رو بازتولید کنه. که اینا همون Huffman coding در بحث قبلی هستن.
همونطور که گفته شد، webP اینکار از طریق یه جدولی که بهش huffman_table میگن، انجام میده، اما خود جداول میتونن خیلی بزرگ باشن و قراردادنشون کنار تصویر فشرده شده، باعث افزایش اندازه فایل میشه. راه حل این مشکل اینه که خود جداول رو هم با Huffman coding ، فشرده کنه.
با این تعاریف، تخصیص حافظه، محتملترین نامزد برای سرریز شدن هستش.
طرح اینه که تخصیص huffman_tables در ReadHuffmanCodes رو سرریز کنیم، ایده برای این کار هم اینه که از فراخوانی VP8LBuildHuffmanTable/BuildHuffmanTable در ReadHuffmanCode (نه در ReadHuffmanCodeLengths) ، برای تغییر مقدار huffman_table از اندازه بافر از پیش محاسبه شده، استفاده کنیم. برای پیچیدگی کار، این در نظر بگیرید که 5 بخش مختلف از جدول هافمن، وجود داره که هر کدوم اندازه مختلفی دارن و احتمالا باید هر 5 بخش رو ایجاد کنیم تا به اندازه ی کافی به انتهای بافر نزدیک بشیم که بتونیم سرریز رو انجام بدیم.
محقق با ارتباطی که با mistymntncop داشته متوجه شده که اونا هم دارن روی این آسیب پذیری کار میکنن و یه harness code برای ایجاد WebP با داده های دلخواه Huffman coding (“code lengths”) توسعه دادن. محقق اونو تست کرده و کار کردش تایید کرده، در این مرحله میتونسته یه آرایه دلخواه code_lengths برای فراخوانی BuildHuffmanTable ارسال کنه.
code_lengths یه بافر موقت از پیش تخصیص یافته هستش که برای ایجاد جدول هافمن مورد استفاده قرار میگیره.
چالش بعدی این بود که بشه گروهی از code_lengths رو پیدا کنن که باعث بشه ، BuildHuffmanTable از اندازه بافر از پیش محاسبه شده، بیشتر بشه. این کار رو بصورت دستی انجام داده یعنی آرایه code_lengths رو تغییر دادن تا روی هیستوگرام داخلی تاثیر بزاره (در اصل روی آرایه count در BuildHuffmanTable تاثیر بزاره) و بعدش بررسی تاثیر هر یک از 16 ورودی هیستوگرام روی total_size ، که متغیری هستش که ما باید ، به مقداری بزرگتر از حد انتظار افزایش بدیم.
طی این بررسی محقق متوجه شده که یه تعامل پیچیده بین حالت شروع هیستوگرام، وضعیت آماری درخت (num_open and num_nodes) و متغیر key که مکان شروع ReplicateValue رو ردیابی میکنه که ورودی هایی رو در جدول نوشته که ما میخواییم سرریزش کنیم، وجود داره. این پیچیدگی و نداشتن اطلاعات در خصوص درخت های هافمن و انتخاب پیاده سازی های خاص webP باعث شده تا محقق نتونه ورودی قابل اطمینانی حتی برای ایجاد یه BuildHuffmanTable درست بسازه چه برسه به اینکه یه BuildHuffmanTable بزرگتر بسازه.
محقق رفته سراغ ایده بروت فورس. محقق متوجه شده که 9 ورودی اول هیستوگرام (count[0] .. count[8 که بهش root table میگن) تاثیر زیادی روی total_size نداره، اما میتونن در محاسبات داخلی تاثیر بزارن. ورودی های آخر هیستوگرام (count[9] .. count[15] که بهشون second level tables میگن) تاثیر مستقیمی روی مقدار نهایی total_size دارن. محقق اومده برای root tableها مقادیر کم و برای second level tables مقادیر بالا در نظر گرفته بنابراین تونسته ورودی های صحیحی رو پیدا کنه که برخیشون جداول خروجی بزرگتری رو هم ایجاد میکردن اما هنوز از اندازه بافر از پیش محاسبه شده ، کمتر بودن.
محقق رفته سراغ اینکه این مقادیر از پیش ساخته شده چطوری ایجاد میشن. بسته به تعداد color cache bits که مشخص شدن، چندین اندازه مختلف از پیش محاسبه شده، وجود داره. اندازه ها در kTableSize تعریف شدن که شامل مقادیر و یه نکته کلیدی : همه مقادیر محاسبه شده برای جسجوی سطح اول 8 بیتی با ابزار enough از Mark Adler انجام شده.
این ابزار enough ، هیستوگرام رو برای بزرگترین جدول جستجوی درخت هافمن ممکن ، برای هر سایز الفبای معین و اندازه root table و حداکثر طول کد ، ارائه میکنه. حالا با استفاده از ابزار enough ، محقق میتونه اندازه های بافر از پیش محاسبهشده ی مختلف رو بدست بیاره، و با استفاده از ابزار mistymntncop میتونه تأیید کنه که طولهای کد خاص منتشر شده توسط “enough ” صد درصد فضای نخصیصی huffman_tables رو پر میکنن. اما کل ایده heap overflow اینه که بتونیم تخصیص رو تا 101٪ پر کنیم که منجر به سرریز بشه.
نکته مهم دیگه این که ، ابزار enough برای اندازه های color_cache تا 8 بیت کار میکنه، بنابراین محقق اومده اونو دستکاری کرده تا مقادیر بیشتر از 8 بیت رو هم ساپورت کنه.
محقق با بررسی متوجه شده که حداکثر اندازه ادعا شده برای سایز symbol 40 با root table هشت بیتی و حداکثر طول کد 15، 410 هستش . اگه بتونیم چیزی بزرگتر از 410 تولید کنیم، بازی رو بردیم. اما هیچ یک از کدهایی که BuildHuffmanTable ، معتبر در نظر میگیره، سایزشون بزرگتر از 410 نیست . به نظر میرسه ، بررسی سازگاری در انتهای BuildHuffmanTable، مثلا بررسی اینکه تعداد گره های خروجی یه مقدار مورد انتظاره، تضمین میکنه که کدهای پذیرفته شده مطابق با ابزار enough و اندازه های بافر از پیش محاسبه شده ای هستن که بهشون داده .
تابع BuildHuffmanTable با استفاده از ReplicateValue ، مقادیر رو در جدول خروجی مینویسه. اگه 4 درخت هافمن معتبر بسازیم که منجر به 4 جدول خروجی با اندازه ماکزیمم بشه، و بعدش یه درخت هافمن نامعتبر رو برای آخرین جدول ارائه کنیم ، میتونیم یه out-of-bounds write توسط تابع ReplicateValue از یه key با شروع نامعتبر ، قبل از بررسی نهایی تعداد گرهها داشته باشیم.
کد زیر نحوه بازتولید باگ رو نشون میده :
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 |
# checkout webp $ git clone https://chromium.googlesource.com/webm/libwebp/ webp_test $ cd webp_test/ # checkout vulnerable version $ git checkout 7ba44f80f3b94fc0138db159afea770ef06532a0 # enable AddressSanitizer $ sed -i 's/^EXTRA_FLAGS=.*/& -fsanitize=address/' makefile.unix # build webp $ make -f makefile.unix $ cd examples/ # fetch mistymntncop's proof-of-concept code $ wget https://raw.githubusercontent.com/mistymntncop/CVE-2023-4863/main/craft.c # build and run proof-of-concept $ gcc -o craft craft.c $ ./craft bad.webp # test trigger file $ ./dwebp bad.webp -o test.png ================================================================= ==207551==ERROR: AddressSanitizer: heap-buffer-overflow on address 0x626000002f28 at pc 0x56196a11635a bp 0x7ffd3e5cce90 sp 0x7ffd3e5cce80 WRITE of size 1 at 0x626000002f28 thread T0 #0 0x56196a116359 in BuildHuffmanTable (/home/isosceles/source/webp/webp_test/examples/dwebp+0xb6359) #1 0x56196a1166e7 in VP8LBuildHuffmanTable (/home/isosceles/source/webp/webp_test/examples/dwebp+0xb66e7) #2 0x56196a0956ff in ReadHuffmanCode (/home/isosceles/source/webp/webp_test/examples/dwebp+0x356ff) #3 0x56196a09a2b5 in DecodeImageStream (/home/isosceles/source/webp/webp_test/examples/dwebp+0x3a2b5) #4 0x56196a09e216 in VP8LDecodeHeader (/home/isosceles/source/webp/webp_test/examples/dwebp+0x3e216) #5 0x56196a0a011b in DecodeInto (/home/isosceles/source/webp/webp_test/examples/dwebp+0x4011b) #6 0x56196a0a2f06 in WebPDecode (/home/isosceles/source/webp/webp_test/examples/dwebp+0x42f06) #7 0x56196a06c026 in main (/home/isosceles/source/webp/webp_test/examples/dwebp+0xc026) #8 0x7f7ea8a8c082 in __libc_start_main ../csu/libc-start.c:308 #9 0x56196a06e09d in _start (/home/isosceles/source/webp/webp_test/examples/dwebp+0xe09d) 0x626000002f28 is located 0 bytes to the right of 11816-byte region [0x626000000100,0x626000002f28) allocated by thread T0 here: #0 0x7f7ea8f2d808 in __interceptor_malloc ../../../../src/libsanitizer/asan/asan_malloc_linux.cc:144 #1 0x56196a09a0eb in DecodeImageStream (/home/isosceles/source/webp/webp_test/examples/dwebp+0x3a0eb) SUMMARY: AddressSanitizer: heap-buffer-overflow (/home/isosceles/source/webp/webp_test/examples/dwebp+0xb6359) in BuildHuffmanTable ... |
شکل زیر درخت هافمن این آنالیز رو نشون میده که توسط ابزاری که توسط mistymntncop توسعه داده شده ، ایجاد شده :
بطور خلاصه این آسیب پذیری اینجوریه که یه فایل مخرب WebP که بصورت lossless فشرده شده، باعث میشه، libwebp داده هارو خارج از محدوده هیپ بنویسه. تابع ReadHuffmanCodes بافر HuffmanCode رو با اندازه هایی از یه آرایه از پیش محاسبه شده بنام kTableSize تخصیص میده. مقدار color_cache_bits مشخص میکنه که چه اندازه ای استفاده میشه. آرایه kTableSize اندازه هارو فقط برای جستجوی جدول سطح اول 8 بیتی در نظر میگیره و نه برای سطح دوم. libwebp حداکثر امکان استفاده از 15 بیت کد (MAX_ALLOWED_CODE_LENGTH) رو میده. وقتی BuildHuffmanTable میخواد جدول سطح دوم رو پر کنه، ممکنه منجر به out-of-bound write بشه. این out-of-bound write در آرایه کوچکتر از اندازه معمول در ReplicateValue اتفاق می افته.
برای این آسیب پذیری یه PoC منتشر شده که میتونید از اینجا مشاهده کنید.
فازینگ برای کشف آسیب پذیری :
بعد از اینکه گوگل ، این آسیب پذیری رو در کروم اصلاح کرد، یسری بحث ها در خصوص فازینگ بین محققا مطرح شد. یه باینری که با زبان سی برنامه نویسی شده، معمولا یه هدف خوب برای فازینگ هستش. اما چرا این آسیب پذیری قبلا با فازینگ کشف نشده؟
پروژه OSS-Fuzz گوگل ، صدها کتابخونه متن باز از جمله libwebp رو برای سالیان متمادی فاز کرده.
علت این پیدا نشدن به دلیل پیچیدگی این فرمت و پیش شرطهای زیاد برای فعال کردن این آسیب پذیری هستش. از بین میلیاردها احتمال، ما باید ،یه دنباله از 4 جدول معتبر هافمن بسازیم که حداکثر اندازه اشون برای دو اندازه alphabet مختلف (280 و 256) باشه، قبل از اینکه نوع بسیار خاصی از جدول هافمن نامعتبر رو با اندازه alphabet سوم (40) بسازیم. اگه در هر مرحله یه بیت اشتباه باشه، دیکدر تصویر ، خطا میده و اتفاق خاصی نمی افته.
یکی از کارهایی که گوگل بعد از اصلاح این آسیب پذیری انجام داده، یه فازر مختص برای روتین های هافمن در WebP توسعه داده. محقق این فازر رو اجرا کرده اما نتونسته آسیب پذیری رو کشف کنه.
این آسیب پذیری رو با یه آسیب پذیری قدیمی بنام باگ Load_SBit_Png در FreeType مقایسه کردن که در یه اکسپلویت پیشرفته زیرودی کشف شده بود. شباهتهایی که بین این دو هست اینه که آسیب پذیری یه heap overflow در یه کتابخونه ای هستش که به زبان سی نوشته شده، کروم رو تحت تاثیر قرار داده بود و همچنین FreeType برای ماهها و سالها مورد فاز قرار گرفته بود.
این آسیب پذیری هم توسط فازینگ کشف نشده بود، اما علت این عدم کشف ، نبود harness کافی بوده. اگه harnessهای فازی زودتر بروز شده بودن، تا بشه از APIها بهتر استفاده کرد، این باگ با فازینگ قابل کشف بود.
اما این امر در خصوص WebP 0day (CVE-2023-4863) صدق نمیکنه، مگه اینکه یسری fuzzing corpus نزدیک به باگ داشتیم که اگه یکمی خوش شانس بودیم، میتونستیم این آسیب پذیری رو کشف کنیم.
محقق معتقد که این آسیب پذیری به احتمال زیاد از طریق ارزیابی دستی کد کشف شده. در ارزیابی کد، تخصیص huffman_tables رو مشاهده کردن که در طول تجزیه هدر فایل VP8L رخ میده، بنابراین دنبال استفاده از اون میرید و در ادامه میتونید آسیب پذیری رو فعال کنید.
منابع: